Edit: you can jump to #1
Today I bought data that is in ASCII format. The import of the data works. However, the loading times are extremely long.
Here is a description of how much data i used in the current context.
I copied the NASDAQ 100 symbols into a folder from the existing data. I am talking about 101 text files with a total size of 7.68 gigabytes. (1-minute frequency)
I managed to backtest two strategies with it over several periods of time. However, the data manager has problems displaying the data (detailed information) even though the symbols are listed. In advance, I have of course also tested the functions with fewer symbols.
EDITED !
I'm sorry to modify my introduction, but after restarting WL, all this "bla" makes no sense anymore. So i shorten it.
I was not able to see binary files in the AsciiCache folder. After restart of WL the binary files occured. The loading times seem quite high, but simply seem to be related to the content.
Today I bought data that is in ASCII format. The import of the data works. However, the loading times are extremely long.
Here is a description of how much data i used in the current context.
I copied the NASDAQ 100 symbols into a folder from the existing data. I am talking about 101 text files with a total size of 7.68 gigabytes. (1-minute frequency)
I managed to backtest two strategies with it over several periods of time. However, the data manager has problems displaying the data (detailed information) even though the symbols are listed. In advance, I have of course also tested the functions with fewer symbols.
EDITED !
I'm sorry to modify my introduction, but after restarting WL, all this "bla" makes no sense anymore. So i shorten it.
I was not able to see binary files in the AsciiCache folder. After restart of WL the binary files occured. The loading times seem quite high, but simply seem to be related to the content.
Rename
I just restarted WL and Voila, there were suddenly binaries in the AsciiCache directory.
1. It seems a restart is necessary and the *.QX data will be stored when WL is closed, is this correct?
2. So, the "cache" is already a permanent conversion, is that correct?
3. So, the loading time for the data in the strategy is the optimum for now, there is no parsing included, is that correct?
4. If so, this amount of data i was talking about needs 10-15 minutes to load, because of its content, is that correct?
Sometimes it is quite simple after all, lol
1. It seems a restart is necessary and the *.QX data will be stored when WL is closed, is this correct?
2. So, the "cache" is already a permanent conversion, is that correct?
3. So, the loading time for the data in the strategy is the optimum for now, there is no parsing included, is that correct?
4. If so, this amount of data i was talking about needs 10-15 minutes to load, because of its content, is that correct?
Sometimes it is quite simple after all, lol
1. Restart isn't necessary, the QX should appear after caching is done.
2. It's permanent until you decide to update the source ASCII file. When a change is detected, the binary cache will get updated automatically.
3. Yes, that's how it's intended to facilitate the loading of huge intraday ASCII files (over 20K lines).
4. The efficiency depends on several factors like CPU speed, data amount, HDD/SSD.
2. It's permanent until you decide to update the source ASCII file. When a change is detected, the binary cache will get updated automatically.
3. Yes, that's how it's intended to facilitate the loading of huge intraday ASCII files (over 20K lines).
4. The efficiency depends on several factors like CPU speed, data amount, HDD/SSD.
Thanks for the answers. I would like to report how much data i was refering to.
It was 101 (current NASDAQ 100) files including a total number of 147289916 lines .
When the strategy started the load operation takes about 10 minutes .
EDIT: If the Data Range is not restricted, i.e. "All data" is selected, the loading process takes less than one minute.
I think the waiting time is reasonable. This amount of data can ultimately be used in a final evaluation,
although smaller data sets can also be used during the development of a strategy.
The most important thing is, that WL is able to handle the data cleanly in the strategy context.
I will come back later with two or three minor topics. (updates on dataset, symbol names, data manager).
AAPL.TXT: 2818703
ABNB.TXT: 192409
ADBE.TXT: 1794885
ADI.TXT: 1738437
ADP.TXT: 1727584
ADSK.TXT: 1736508
AEP.TXT: 1724944
ALGN.TXT: 1346640
AMAT.TXT: 1866237
AMD.TXT: 2317847
AMGN.TXT: 1800339
AMZN.TXT: 2052140
ANSS.TXT: 1359592
ASML.TXT: 1412310
ATVI.TXT: 1558978
AVGO.TXT: 657510
AZN.TXT: 1607799
BIDU.TXT: 1903052
BIIB.TXT: 1736790
BKNG.TXT: 1310928
CDNS.TXT: 1609853
CEG.TXT: 734654
CHTR.TXT: 1022820
CMCSA.TXT: 1899943
COST.TXT: 1551063
CPRT.TXT: 1565591
CRWD.TXT: 347339
CSCO.TXT: 2176264
CSX.TXT: 1846502
CTAS.TXT: 1603600
CTSH.TXT: 1839505
DDOG.TXT: 295626
DLTR.TXT: 1505969
DOCU.TXT: 442381
DXCM.TXT: 1314049
EA.TXT: 1533164
EBAY.TXT: 1866886
EXC.TXT: 1742075
FAST.TXT: 1709077
FISV.TXT: 1689429
FTNT.TXT: 1197651
GILD.TXT: 1893004
GOOGL.TXT: 1625245
HON.TXT: 1745761
IDXX.TXT: 1291101
ILMN.TXT: 1608978
INTC.TXT: 2170261
INTU.TXT: 1717393
ISRG.TXT: 1346352
JD.TXT: 966728
KDP.TXT: 1367696
KHC.TXT: 728935
KLAC.TXT: 1722973
LCID.TXT: 304379
LRCX.TXT: 1750208
LULU.TXT: 1463114
MAR.TXT: 1730737
MCHP.TXT: 1731811
MDLZ.TXT: 1539500
MELI.TXT: 1207611
META.TXT: 1533540
MNST.TXT: 1703524
MRNA.TXT: 459047
MRVL.TXT: 1826228
MSFT.TXT: 2224135
MTCH.TXT: 634984
MU.TXT: 2108773
NFLX.TXT: 1999112
NTES.TXT: 1575174
NVDA.TXT: 2122188
NXPI.TXT: 1168019
ODFL.TXT: 1422594
OKTA.TXT: 504098
ORLY.TXT: 1560637
PANW.TXT: 948652
PAYX.TXT: 1688467
PCAR.TXT: 1717868
PDD.TXT: 494152
PEP.TXT: 1763915
PYPL.TXT: 801360
QCOM.TXT: 1919033
REGN.TXT: 1529974
ROST.TXT: 1725862
SBUX.TXT: 1864571
SGEN.TXT: 1356169
SIRI.TXT: 2004899
SNPS.TXT: 1601758
SPLK.TXT: 993536
SWKS.TXT: 1768982
TEAM.TXT: 596107
TMUS.TXT: 1508899
TSLA.TXT: 1611046
TXN.TXT: 1796891
VRSK.TXT: 1110069
VRSN.TXT: 1640892
VRTX.TXT: 1708441
WBA.TXT: 779340
WDAY.TXT: 930342
XEL.TXT: 1704857
ZM.TXT: 383968
ZS.TXT: 428953
It was 101 (current NASDAQ 100) files including a total number of 147289916 lines .
When the strategy started the load operation takes about 10 minutes .
EDIT: If the Data Range is not restricted, i.e. "All data" is selected, the loading process takes less than one minute.
I think the waiting time is reasonable. This amount of data can ultimately be used in a final evaluation,
although smaller data sets can also be used during the development of a strategy.
The most important thing is, that WL is able to handle the data cleanly in the strategy context.
I will come back later with two or three minor topics. (updates on dataset, symbol names, data manager).
AAPL.TXT: 2818703
ABNB.TXT: 192409
ADBE.TXT: 1794885
ADI.TXT: 1738437
ADP.TXT: 1727584
ADSK.TXT: 1736508
AEP.TXT: 1724944
ALGN.TXT: 1346640
AMAT.TXT: 1866237
AMD.TXT: 2317847
AMGN.TXT: 1800339
AMZN.TXT: 2052140
ANSS.TXT: 1359592
ASML.TXT: 1412310
ATVI.TXT: 1558978
AVGO.TXT: 657510
AZN.TXT: 1607799
BIDU.TXT: 1903052
BIIB.TXT: 1736790
BKNG.TXT: 1310928
CDNS.TXT: 1609853
CEG.TXT: 734654
CHTR.TXT: 1022820
CMCSA.TXT: 1899943
COST.TXT: 1551063
CPRT.TXT: 1565591
CRWD.TXT: 347339
CSCO.TXT: 2176264
CSX.TXT: 1846502
CTAS.TXT: 1603600
CTSH.TXT: 1839505
DDOG.TXT: 295626
DLTR.TXT: 1505969
DOCU.TXT: 442381
DXCM.TXT: 1314049
EA.TXT: 1533164
EBAY.TXT: 1866886
EXC.TXT: 1742075
FAST.TXT: 1709077
FISV.TXT: 1689429
FTNT.TXT: 1197651
GILD.TXT: 1893004
GOOGL.TXT: 1625245
HON.TXT: 1745761
IDXX.TXT: 1291101
ILMN.TXT: 1608978
INTC.TXT: 2170261
INTU.TXT: 1717393
ISRG.TXT: 1346352
JD.TXT: 966728
KDP.TXT: 1367696
KHC.TXT: 728935
KLAC.TXT: 1722973
LCID.TXT: 304379
LRCX.TXT: 1750208
LULU.TXT: 1463114
MAR.TXT: 1730737
MCHP.TXT: 1731811
MDLZ.TXT: 1539500
MELI.TXT: 1207611
META.TXT: 1533540
MNST.TXT: 1703524
MRNA.TXT: 459047
MRVL.TXT: 1826228
MSFT.TXT: 2224135
MTCH.TXT: 634984
MU.TXT: 2108773
NFLX.TXT: 1999112
NTES.TXT: 1575174
NVDA.TXT: 2122188
NXPI.TXT: 1168019
ODFL.TXT: 1422594
OKTA.TXT: 504098
ORLY.TXT: 1560637
PANW.TXT: 948652
PAYX.TXT: 1688467
PCAR.TXT: 1717868
PDD.TXT: 494152
PEP.TXT: 1763915
PYPL.TXT: 801360
QCOM.TXT: 1919033
REGN.TXT: 1529974
ROST.TXT: 1725862
SBUX.TXT: 1864571
SGEN.TXT: 1356169
SIRI.TXT: 2004899
SNPS.TXT: 1601758
SPLK.TXT: 993536
SWKS.TXT: 1768982
TEAM.TXT: 596107
TMUS.TXT: 1508899
TSLA.TXT: 1611046
TXN.TXT: 1796891
VRSK.TXT: 1110069
VRSN.TXT: 1640892
VRTX.TXT: 1708441
WBA.TXT: 779340
WDAY.TXT: 930342
XEL.TXT: 1704857
ZM.TXT: 383968
ZS.TXT: 428953
As already mentioned here a small inconvenience.
The data manager takes a very long time to "load" the (amount of) data. I suspect the loading process here behaves differently than when data is loaded in the strategy. Finally, no detailed information is displayed. I have tried several times since yesterday.
Maybe you have experience with datasets of this size and can give me a useful hint.
Fortunately, that's the only problem I've encountered so far. The other points relate to the handling, I can also benefit from a few tips.
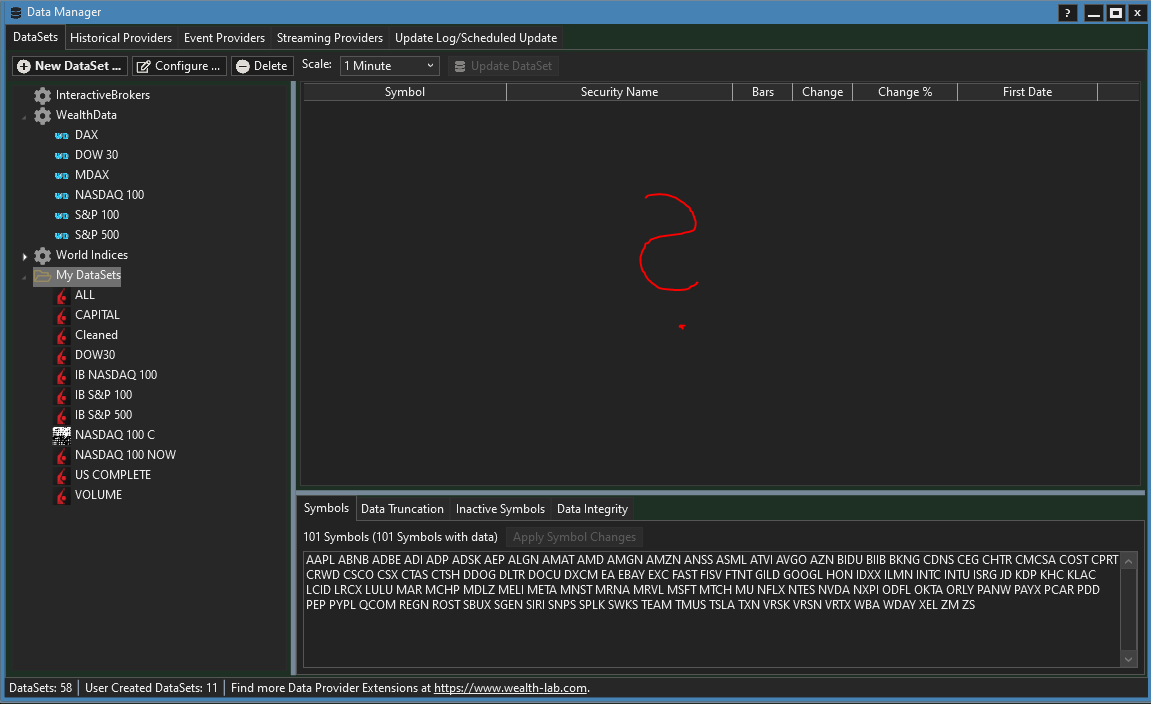
The data manager takes a very long time to "load" the (amount of) data. I suspect the loading process here behaves differently than when data is loaded in the strategy. Finally, no detailed information is displayed. I have tried several times since yesterday.
Maybe you have experience with datasets of this size and can give me a useful hint.
Fortunately, that's the only problem I've encountered so far. The other points relate to the handling, I can also benefit from a few tips.
With "My DataSets" highlighted, I would not expect anything to be shown in this table.
Using mousover (the datasets) always highlights the folder too. Do you really think, i did not click the dataset, come on.
After the dataset is successfully loaded, only the dataset is highlighted. But this does not happen.
Also, the symbols are listed ;-), so where is the information?
Responses like that just get me excited.
As i mentioned i tried to load the data several times, each time 30-60 minutes with the above result, wasting my time serveral hours.
And this is your "professionel" answer. Do you think that the symbols shown drop out of nowhere?
This is the picture after the load finished/failed. Exactly like that!
(with the "My Datasets" highlighted)
After the dataset is successfully loaded, only the dataset is highlighted. But this does not happen.
Also, the symbols are listed ;-), so where is the information?
Responses like that just get me excited.
As i mentioned i tried to load the data several times, each time 30-60 minutes with the above result, wasting my time serveral hours.
And this is your "professionel" answer. Do you think that the symbols shown drop out of nowhere?
This is the picture after the load finished/failed. Exactly like that!
(with the "My Datasets" highlighted)
I anticipate the next profound question. "Is the data really there?" Surprise: yes. I've even done backtests on the non-existent data, magically.
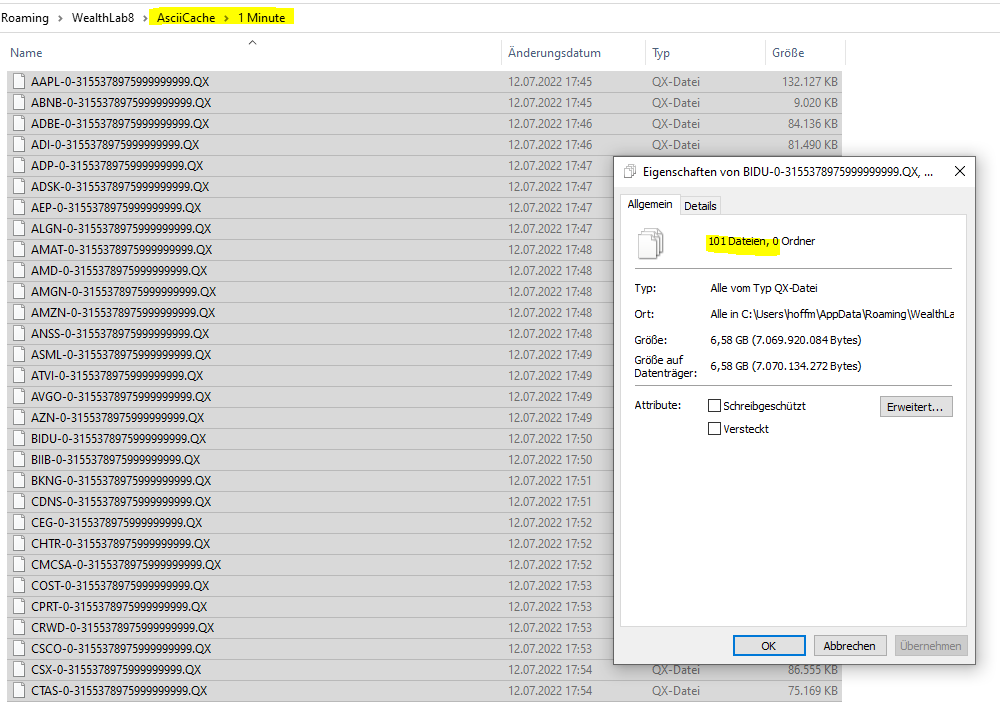
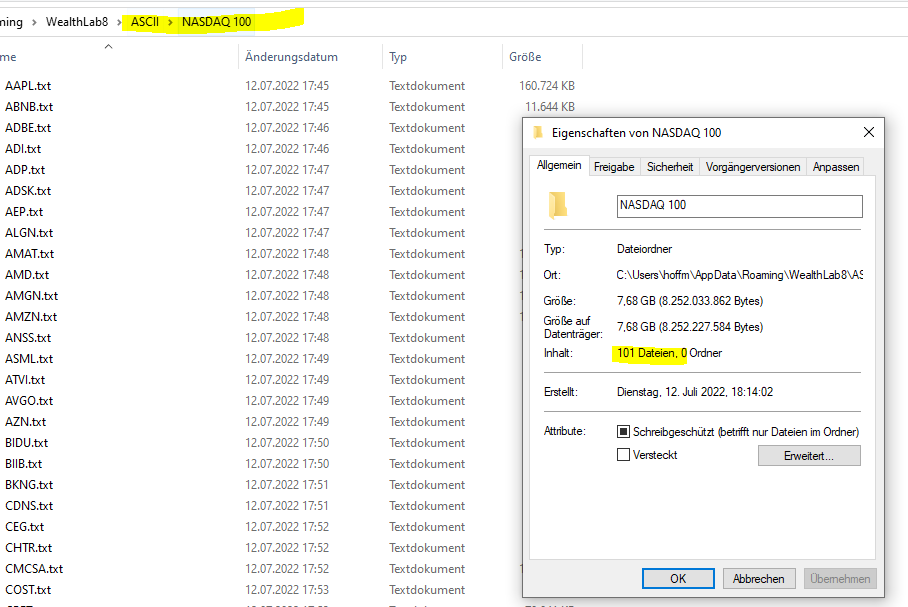
QUOTE:
about needs 10-15 minutes to load
This time seems long to me for a binary file. Are we storing the binaries in Int32 format say to the nearest 1/10th of a cent? That would be the best native .NET framework data type to use.
The obvious solution would be to use data compression. Since we are dealing with a time series, the deltas between neighboring points is small, so there's a tremendous opportunity to compress this time series data! The PNG image format uses Laplacian Pyramid compression, but you don't have to get that fancy. Perhaps if you Googled "lossless time series compression" you should get some hits. The next question is whether or not there's a NuGet package that does this for a simple time series?
There are some compression formats established by Illinois Supercomputer. These formats are really established for laboratory data in multiple time scales and sources. But they do have code packages for them. A number of analytical packages (e.g. MatLab) can read them. However, they are probably over generalized (i.e. overkill) for a targeted application like WL.
Hello superticker.
Maybe you have already seen (#3), that loading "All data" is ten times faster.
Obviously, at least from the outside, the data is checked for the date (data range) during the loading process. So there are operations on the data. Conceptually, one could also always load the data completely and suppress signals that are not in the data range during runtime. The concrete check whether this can be realized depends of course on the current implementation.
Maybe you have already seen (#3), that loading "All data" is ten times faster.
Obviously, at least from the outside, the data is checked for the date (data range) during the loading process. So there are operations on the data. Conceptually, one could also always load the data completely and suppress signals that are not in the data range during runtime. The concrete check whether this can be realized depends of course on the current implementation.
@MIH
Are there subfolders for any other bar scales that read like "2 Minute", "12 Minute" etc. in the AsciiCache folder?
Are there subfolders for any other bar scales that read like "2 Minute", "12 Minute" etc. in the AsciiCache folder?
The directory structure looks like this,
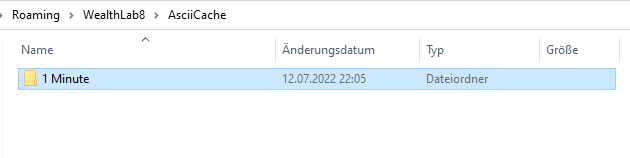
QUOTE:
Do you think that the symbols shown drop out of nowhere?
In theory, the "101 symbols" can be a leftover of you highlighting an ASCII DataSet before the long delay. I recall fixing a related issue in this code (it shouldn't be there anymore). So as you see, there was reason behind my response.
I leave the verdict on what's going here to Dion though because no one knows better.
I don't have any immediate insights, Eugene. I think we'll need to spend some time investigating.
Thank you for taking care of this. My last points fall within the "best practice" category.
Here is the first one ...
With a simple change, I renamed the symbols. The naming convention for the files is "Symbol_1-min.txt".
I changed that to "Symbol.txt" via the command line.
Intuitively, I thought this would be advantageous, for example, if I create datasets with symbols that I then want to stream in a live session. Whether this is useful is hard to judge. A counterpoint, of course, is that I have to do all the updates to the data regularly with each update.
What do you guys think, is there more of an advantage or disadvantage to customizing the filenames/symbols?
@Glitch: Thanks Glitch. Just let me know if you need information from my side.
Here is the first one ...
With a simple change, I renamed the symbols. The naming convention for the files is "Symbol_1-min.txt".
I changed that to "Symbol.txt" via the command line.
Intuitively, I thought this would be advantageous, for example, if I create datasets with symbols that I then want to stream in a live session. Whether this is useful is hard to judge. A counterpoint, of course, is that I have to do all the updates to the data regularly with each update.
What do you guys think, is there more of an advantage or disadvantage to customizing the filenames/symbols?
@Glitch: Thanks Glitch. Just let me know if you need information from my side.
@MIH, this "best practices" question raises an interesting point but goes off topic which is ASCII cache. Though I may have a suggestion if you care to start a new topic?
Let's do it.
Before I open another thread I have my last point. It falls at least partly into the current topic. Let's see...
The historical data, which I have stored initially, should be updated regularly.
Since the file names of the original data are identical with the name of the update, one must consider in advance how to integrate the new data.
The first possibility is to set up a job that merges the files. I think this process is error-prone and time-consuming, because the files are already large.
The second idea I have is that I solve this via a folder structure per symbol. This allows the same file name to be used in multiple directories. Prerequisite that this works is that all directories are scanned. I know that this is possible. What I do not know is whether the data for a symbol from multiple files after loading really takes into account all records (rows).
Example:
20220713_AAL/AAL.txt (historical main file)
20220714_AAL/AAL.txt (update file)
The third possibility, how this is solved by others, you tell me now for sure :-)
And what influence do such updates have on the "cached" files?
The historical data, which I have stored initially, should be updated regularly.
Since the file names of the original data are identical with the name of the update, one must consider in advance how to integrate the new data.
The first possibility is to set up a job that merges the files. I think this process is error-prone and time-consuming, because the files are already large.
The second idea I have is that I solve this via a folder structure per symbol. This allows the same file name to be used in multiple directories. Prerequisite that this works is that all directories are scanned. I know that this is possible. What I do not know is whether the data for a symbol from multiple files after loading really takes into account all records (rows).
Example:
20220713_AAL/AAL.txt (historical main file)
20220714_AAL/AAL.txt (update file)
The third possibility, how this is solved by others, you tell me now for sure :-)
And what influence do such updates have on the "cached" files?
QUOTE:
And what influence do such updates have on the "cached" files?
As far as ASCII cache is concerned, an update to the source ASCII file will trigger an automatic refresh (creation from scratch) of the binary cache file. Thus, caching can be permanent (as the topic title implies) in the absence of updates.
Ok.
Referring again to my last point. I simply tried it out. Assuming I have not made a mistake in the handling, it does not currently work.
First further simplified, I obviously don't need a folder per symbol. In each folder, of course, (current) data for all symbols can be stored.
Here how I have tested it.
Step 1
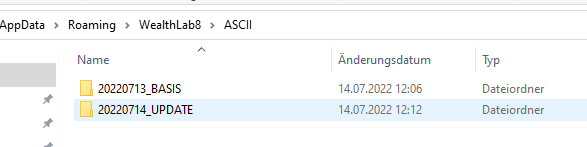

Step 2



It looks like that the latest read of the data will overide the previous symbol information. Appending the data was what i had in mind.
If appending were possible, the data would not have to be changed. In this way, large ASCII data can be used by simply copying it to a subfolder and based on its file name this would allow a simple update process without changing the data itself.
Summary
So here are my findings from this discussion
1. Feature Request - Improving data load (see #9)
2. Bug report - Data Manager does not show detailed information (large data)
3. Symbol naming conventions (Existing Feature Request - Symbol mapping)
4. Feature Request - Appending ASCII data for equal file names (symbols)
I guess i should open these Feature Request and the bug report explicitely. Is that ok?
Thanks for all the feedback.
Referring again to my last point. I simply tried it out. Assuming I have not made a mistake in the handling, it does not currently work.
First further simplified, I obviously don't need a folder per symbol. In each folder, of course, (current) data for all symbols can be stored.
Here how I have tested it.
Step 1
Step 2
It looks like that the latest read of the data will overide the previous symbol information. Appending the data was what i had in mind.
If appending were possible, the data would not have to be changed. In this way, large ASCII data can be used by simply copying it to a subfolder and based on its file name this would allow a simple update process without changing the data itself.
Summary
So here are my findings from this discussion
1. Feature Request - Improving data load (see #9)
2. Bug report - Data Manager does not show detailed information (large data)
3. Symbol naming conventions (Existing Feature Request - Symbol mapping)
4. Feature Request - Appending ASCII data for equal file names (symbols)
I guess i should open these Feature Request and the bug report explicitely. Is that ok?
Thanks for all the feedback.
Are you asking us to modify the ASCII provider to handle data split in two ASCII files, one small (for the update file) and another huge (the source file)? If you really mean it and if my understanding is correct, then no, this is not going to be considered. This is an unnecessary complication driven by a single-user scenario whereas the design must remain universal to cover many use cases and relatively simple to maintain and support. The solution is to append the update file to the source file on your end with a script and let WL recreate the cache file by reopening the symbol's chart, for example.
Ok, so I have to change the data. I can manage that ...
User perspective
This is exactly what the user does not want to do and it is far away from a single user scenario. A user wants the software to do this, especially if the user does not have the knowledge to merge 7000+ files via scripts.
The software is already able to read the data. To ask the user to modify the contents will introduce errors and dissatisfaction.
Finally also effort in support. You can take my word for that. I was responsible for 500+ customers (companies) and more than 5000 suppliers for operations and support.
A user does not want to repeat/do a job which can be automated (by a software that can do this already to 99%)
The user must perform this error-prone operation regularly, possibly daily.
The effort that a user has thereby permanently is compared to a one-time implementation.
Data is the core of the software and the software is designed to relieve the users.
Conceptual
Please don't tell me that this changes anything conceptually.
Files are read in the directory and subdirectories as before.
The only difference is that a additional mode (not a different) is used when reading the data. If during the loading process for a symbol already data were read, further must be appended. This functionality does not even have to replace the previous one, this is supplementary.
If adding a functionality like "appending mode" for ASCII data is not allowed by your design, you should rethink the design.
To the point, this is not a change of the software but an extension.
The previous behavior can be maintained 100%.
That's a platitude!
It is not a single-user scenario and it covers more use cases than the current software. There is absolut nothing special or unique in the solution. It is 100% general solution concept that does not contradict the existing software behaviour.
The feature request in simple words
If data for a symbol has already been loaded and further data for the symbol is read in the loading process,
it is appended to the existing data set. (Please, now read your own statement again)
Respectfully, thanks for your feedback and opinion.
QUOTE:
...
This is an unnecessary complication driven by a single-user scenario whereas the design must remain universal to cover many use cases and relatively simple to maintain and support.
...
User perspective
This is exactly what the user does not want to do and it is far away from a single user scenario. A user wants the software to do this, especially if the user does not have the knowledge to merge 7000+ files via scripts.
The software is already able to read the data. To ask the user to modify the contents will introduce errors and dissatisfaction.
Finally also effort in support. You can take my word for that. I was responsible for 500+ customers (companies) and more than 5000 suppliers for operations and support.
A user does not want to repeat/do a job which can be automated (by a software that can do this already to 99%)
The user must perform this error-prone operation regularly, possibly daily.
The effort that a user has thereby permanently is compared to a one-time implementation.
Data is the core of the software and the software is designed to relieve the users.
QUOTE:
...
This is an unnecessary complication driven by a single-user scenario whereas the design must remain universal to cover many use cases and relatively simple to maintain and support.
...
Conceptual
Please don't tell me that this changes anything conceptually.
Files are read in the directory and subdirectories as before.
The only difference is that a additional mode (not a different) is used when reading the data. If during the loading process for a symbol already data were read, further must be appended. This functionality does not even have to replace the previous one, this is supplementary.
If adding a functionality like "appending mode" for ASCII data is not allowed by your design, you should rethink the design.
To the point, this is not a change of the software but an extension.
The previous behavior can be maintained 100%.
QUOTE:
...
This is an unnecessary complication driven by a single-user scenario whereas the design must remain universal to cover many use cases and relatively simple to maintain and support.
...
That's a platitude!
It is not a single-user scenario and it covers more use cases than the current software. There is absolut nothing special or unique in the solution. It is 100% general solution concept that does not contradict the existing software behaviour.
The feature request in simple words
If data for a symbol has already been loaded and further data for the symbol is read in the loading process,
it is appended to the existing data set. (Please, now read your own statement again)
Respectfully, thanks for your feedback and opinion.
Your Response
Post
Edit Post
Login is required