I've reviewing all available sample and WL.com strategies in an effort to learn more about Wealth-Lab and algorithm development in general. While going through this process, I initially skipped granular processing thinking it wasn't all that essential. That was a mistake. This post might be useful for anyone new to WL or just trying to learn more about algorithms development / backtesting.
Scenario:
- Strategy: OneNight
............Buy at 2% below the last close using a limit order.
............Sell at market on the following day.
- Dataset:
............Daily bar history
............NASDAQ 100 (WL HDP)
- Position Sizing
............100K starting capital
............10% of equity sizing
............1.1 margin factor
- Benchmark
............SPY
First, I backtested every available strategy 10 times with this same dataset & position sizing using an extension that will soon be available; Bulk Backtest to SQL. Then, I reviewed the resulting metrics. OneNight was one of the top performing strategies.
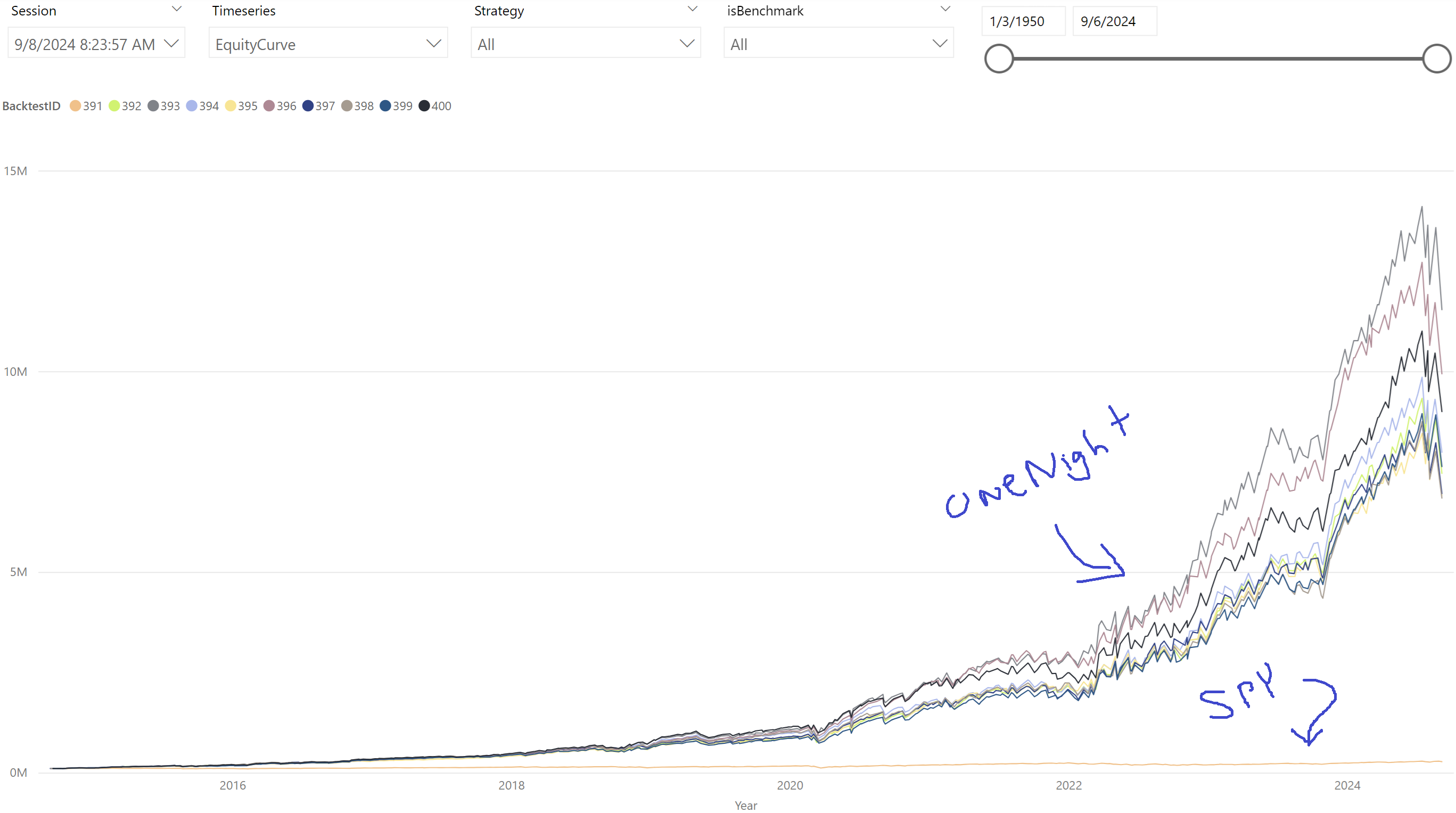
OneNight's 10 year equity curve shows how significantly it out performs SPY.
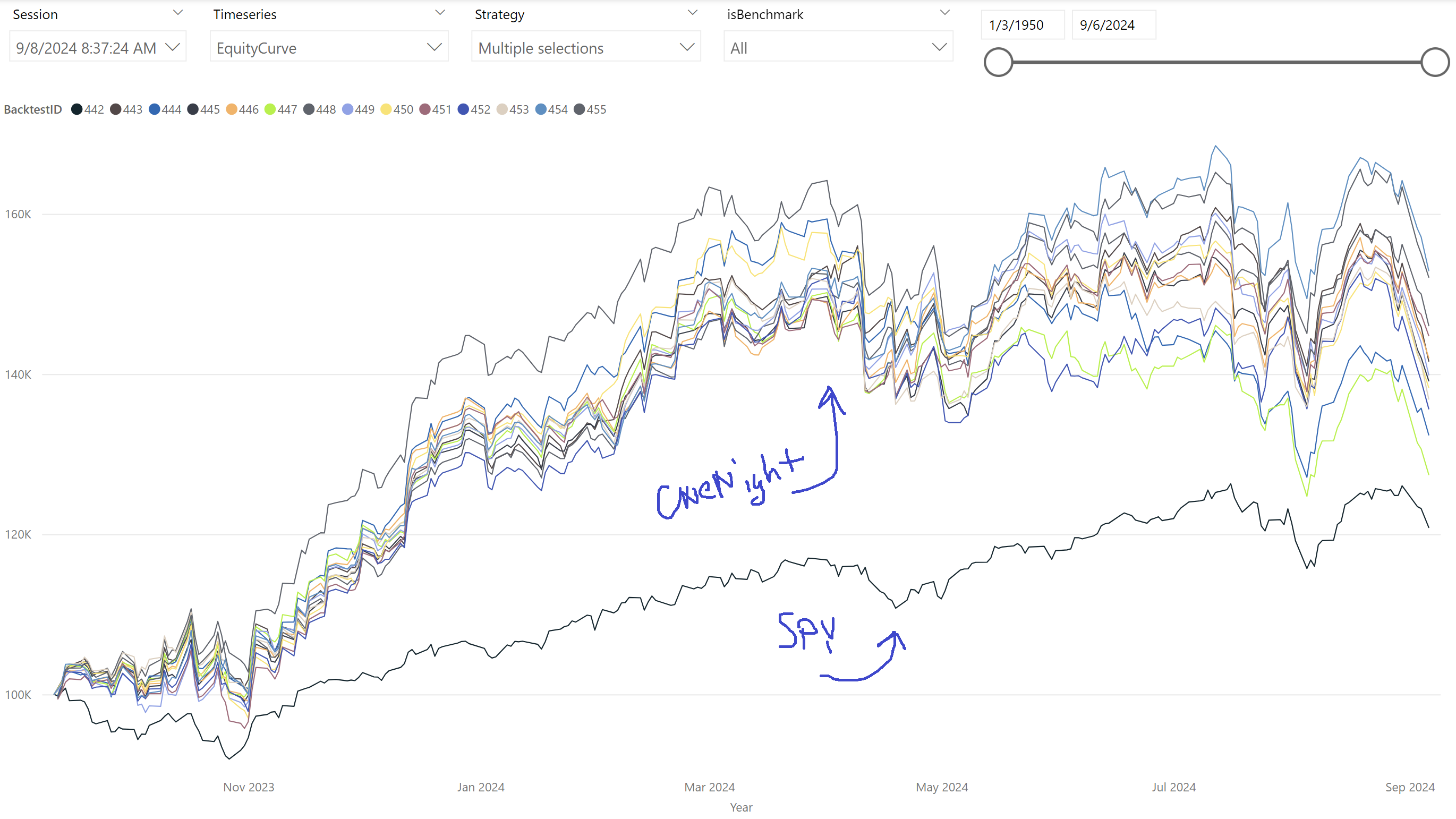
Below is the 1 year performance. OneNight's equity curve significantly outpaces SPY.
Then, I decided to start paper trading OneNight. The first problem was that I didn't have enough buying power to actually implement the strategy in the same way I backtested the strategy. Everyday, the strategy should produce 100 limit buy signals. We want to enter positions in the same way as was backtested. The positions taken are limited to the position sizing settings which will not allow for all signals to generate an active position due to not having enough capital. Which positions are chosen by the backtest? It is random because neither the strategy nor the backtest settings specify which positions will actually be taken and which will be NSF positions.
This led to taking a close look how to manage the 100 signals generated daily. WL's price trigger tool solves this problem by entering limit order only after streaming prices are close to the limit price using a threshold. Great. However, this is not how I backtested. The backtest selected positions randomly, and price triggers will end up selecting positions that first approach the limit price. This is clearly a significant difference.
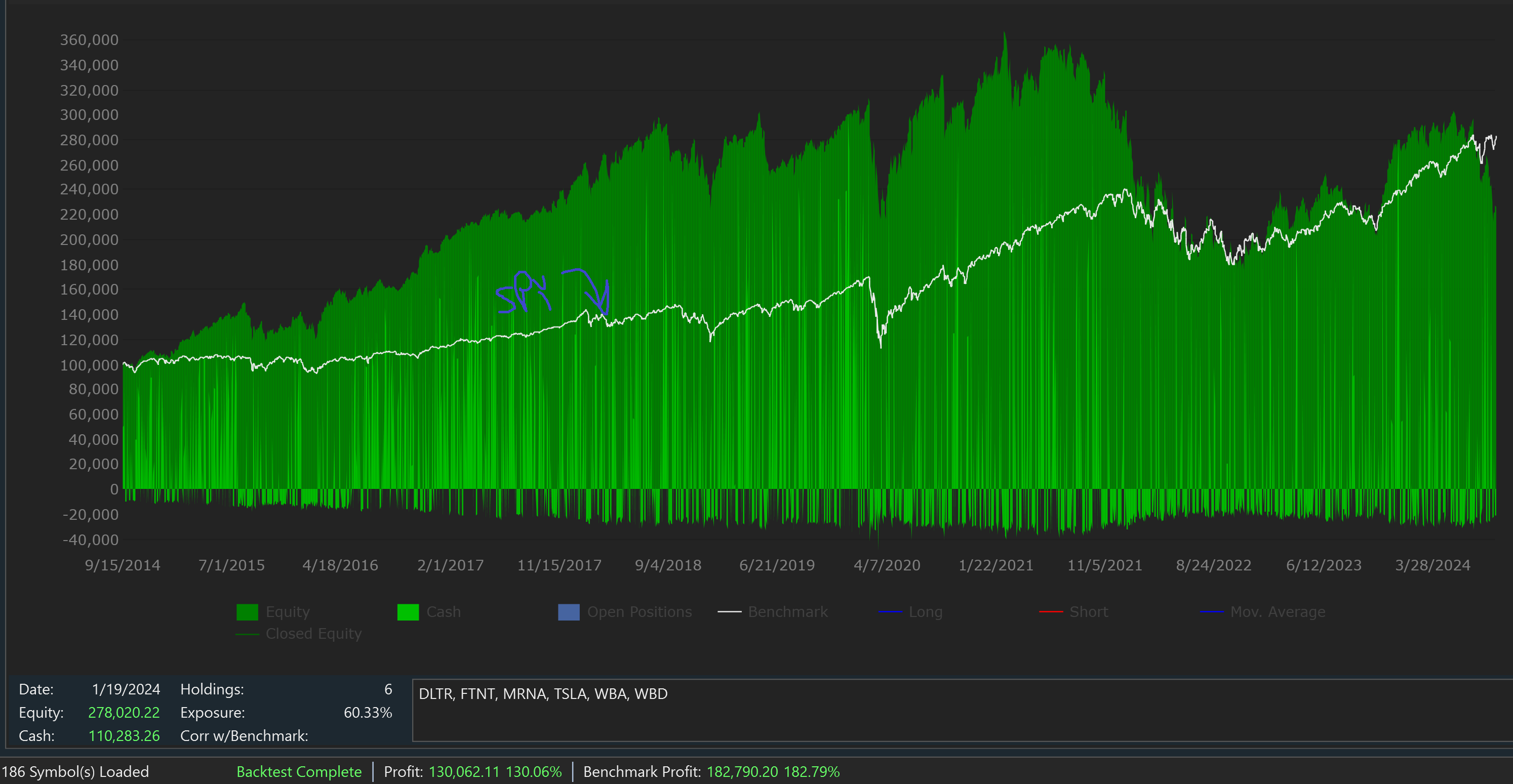
Granular backtesting attempts to solve this the issue. Instead of testing this strategy using daily bars and randomly selecting the signals to turn into positions, we can shift to a lower granularity bar to identify the symbol that first reached the limit price. In my case, I decided to use 1-minute bars as my granular scale. Below are the results.
10 Years of daily bars + 1-Minute granular scale
1 Years of daily bars + 1-Minute granular scale
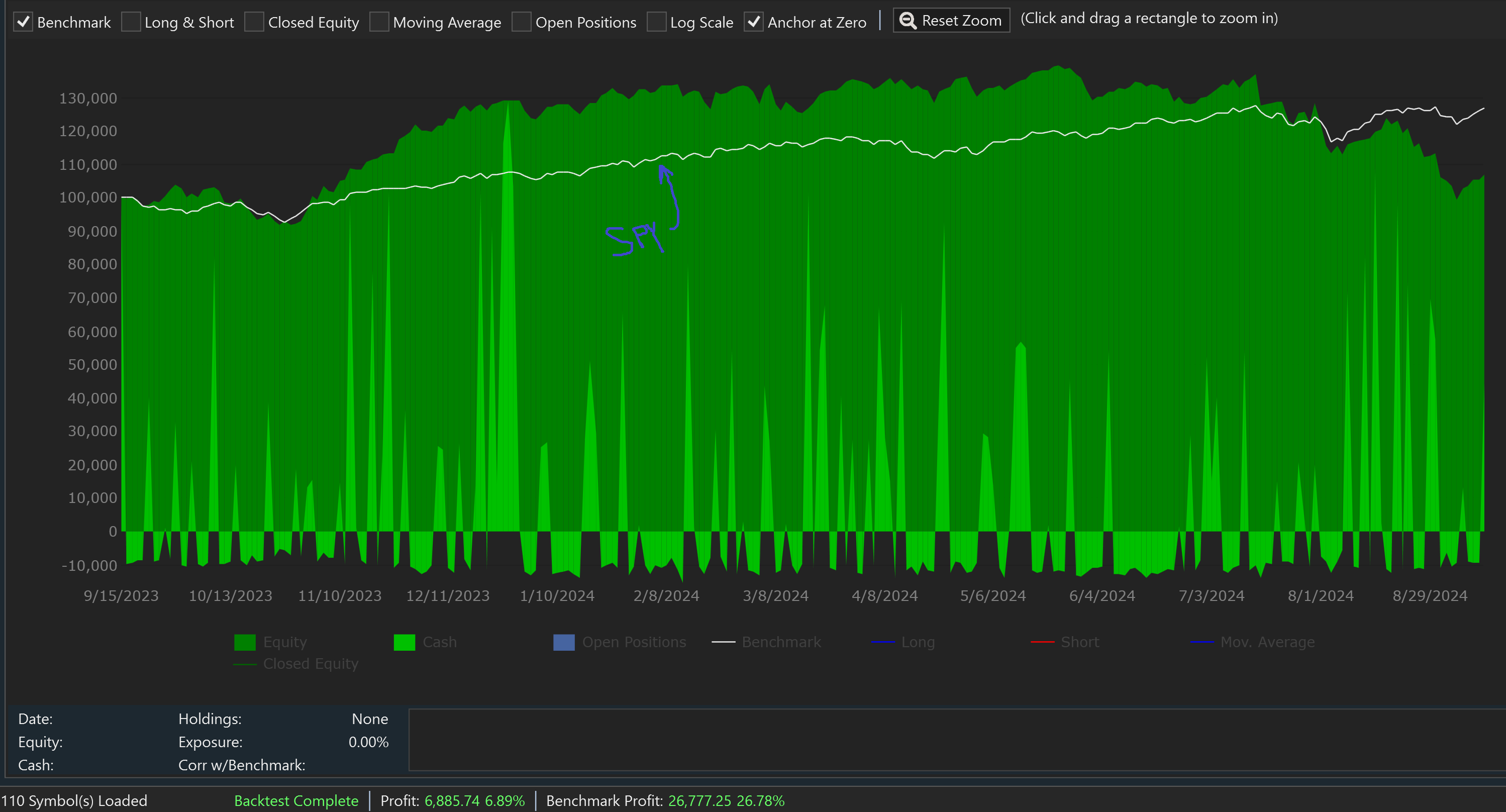
Now things look much different. Why? I can only conclude that random selecting the positions to enter produces significantly better results than selecting those positions that first reach the limit price of 2% below the prior day close. I would not have guessed this, but maybe it makes sense. Maybe the symbols that drop the fastest each day are trading on news that happened over night while the broader set of symbols is influenced by the broader market. One other factor to consider is that I did not load 1-minute bar data for symbols that are no longer listed. I'll try to get this data and retest, but my guess is that we will see worse strategy backtest results after doing so.
Where to go from here? I could search for a way to implement random selection of symbols to enter each day, but this gets very complicated very quickly. Random means we don't know when the symbol reached the 2% below close price. This could have happened at the end of the session, for example, which bring up additional challenges. In practice, it seems nearly impossible to replicate a truly random symbol selection, but maybe some variation could be found. If so, how do I test that variation from random? I'd need to alter the strategy and/or backtest settings to ensure the backtest matches the method that can be implemented.
In conclusion, this whole exercise has been a great learning experience that might be useful to others which is why I'm sharing this. For those that have already been down this road, please do share how you chose to solve for these challenges.
Scenario:
- Strategy: OneNight
............Buy at 2% below the last close using a limit order.
............Sell at market on the following day.
- Dataset:
............Daily bar history
............NASDAQ 100 (WL HDP)
- Position Sizing
............100K starting capital
............10% of equity sizing
............1.1 margin factor
- Benchmark
............SPY
First, I backtested every available strategy 10 times with this same dataset & position sizing using an extension that will soon be available; Bulk Backtest to SQL. Then, I reviewed the resulting metrics. OneNight was one of the top performing strategies.
OneNight's 10 year equity curve shows how significantly it out performs SPY.
Below is the 1 year performance. OneNight's equity curve significantly outpaces SPY.
Then, I decided to start paper trading OneNight. The first problem was that I didn't have enough buying power to actually implement the strategy in the same way I backtested the strategy. Everyday, the strategy should produce 100 limit buy signals. We want to enter positions in the same way as was backtested. The positions taken are limited to the position sizing settings which will not allow for all signals to generate an active position due to not having enough capital. Which positions are chosen by the backtest? It is random because neither the strategy nor the backtest settings specify which positions will actually be taken and which will be NSF positions.
This led to taking a close look how to manage the 100 signals generated daily. WL's price trigger tool solves this problem by entering limit order only after streaming prices are close to the limit price using a threshold. Great. However, this is not how I backtested. The backtest selected positions randomly, and price triggers will end up selecting positions that first approach the limit price. This is clearly a significant difference.
Granular backtesting attempts to solve this the issue. Instead of testing this strategy using daily bars and randomly selecting the signals to turn into positions, we can shift to a lower granularity bar to identify the symbol that first reached the limit price. In my case, I decided to use 1-minute bars as my granular scale. Below are the results.
10 Years of daily bars + 1-Minute granular scale
1 Years of daily bars + 1-Minute granular scale
Now things look much different. Why? I can only conclude that random selecting the positions to enter produces significantly better results than selecting those positions that first reach the limit price of 2% below the prior day close. I would not have guessed this, but maybe it makes sense. Maybe the symbols that drop the fastest each day are trading on news that happened over night while the broader set of symbols is influenced by the broader market. One other factor to consider is that I did not load 1-minute bar data for symbols that are no longer listed. I'll try to get this data and retest, but my guess is that we will see worse strategy backtest results after doing so.
Where to go from here? I could search for a way to implement random selection of symbols to enter each day, but this gets very complicated very quickly. Random means we don't know when the symbol reached the 2% below close price. This could have happened at the end of the session, for example, which bring up additional challenges. In practice, it seems nearly impossible to replicate a truly random symbol selection, but maybe some variation could be found. If so, how do I test that variation from random? I'd need to alter the strategy and/or backtest settings to ensure the backtest matches the method that can be implemented.
In conclusion, this whole exercise has been a great learning experience that might be useful to others which is why I'm sharing this. For those that have already been down this road, please do share how you chose to solve for these challenges.
Rename
Thanks for the post.
You need to go the extra mile with any strategy that has many "NSF Positions". It's easy to take care of that with Transaction.Weight for Market orders. There's even a block condition for that in Block Strategies.
For example, it's common to set the Transaction.Weight to the inverse of RSI (for highest weights) for a long strategy. You sort the signal results and buy the ones at Market with the greatest weights, until buying power runs out.
For a limit order strategy you can't do that so easily, and that's where granular processing comes in. It uses Transaction.Weight too, but it sets the weight according to the time of day that the limit (or stop) price was attained. The earliest time-of-day weights are the signals that the backtester processes first.
You need to go the extra mile with any strategy that has many "NSF Positions". It's easy to take care of that with Transaction.Weight for Market orders. There's even a block condition for that in Block Strategies.
For example, it's common to set the Transaction.Weight to the inverse of RSI (for highest weights) for a long strategy. You sort the signal results and buy the ones at Market with the greatest weights, until buying power runs out.
For a limit order strategy you can't do that so easily, and that's where granular processing comes in. It uses Transaction.Weight too, but it sets the weight according to the time of day that the limit (or stop) price was attained. The earliest time-of-day weights are the signals that the backtester processes first.
Very interesting. Thank you for this. I didn't realize that granular backtesting uses transaction weight in this way.
Your Response
Post
Edit Post
Login is required