While staring at the evolver working through its random choice of strategies I noticed that from time to time an unusually good strategy appears.
Then the evolver creates some child strategy by mutating the genes of this star.
Most of the time the child is worse but it replaces its parent anyway.
(And it may take a long time before a similarly good strategy comes up)
I doubt that this is the best possible thing to do.
I'd suggest to keep the parent strategy: Don't kill the parent!
(This happens (also) with all Filter Sets turned off)
Then the evolver creates some child strategy by mutating the genes of this star.
Most of the time the child is worse but it replaces its parent anyway.
(And it may take a long time before a similarly good strategy comes up)
I doubt that this is the best possible thing to do.
I'd suggest to keep the parent strategy: Don't kill the parent!
(This happens (also) with all Filter Sets turned off)
Rename
Currently the Evolver shows this somewhat frustrating behaviour:
It doesn't work this way. The parent is always retained.
QUOTE:
The parent is always retained.
That is what I would expect.
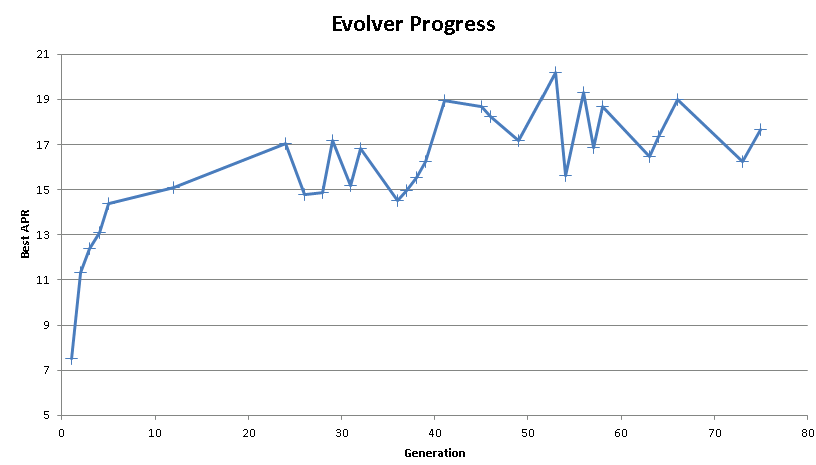
But how comes that the "Best APR" value fluctuates by such a big amount from generation to generation?
Probably because the strategy has NSF positions so the result changes run by run.
If this is the cause...
And the Evolver is evaluating the exact same strategy again and again...
And results change by a big amount because of NSF positions (which are not controllable in any way in the Evolver process)...
... then I'd suggest that the "Best Metric" is not used from the last run (of many runs) but instead some average is calculated for all the runs of this one identical strategy.
... and I'd suggest to use the median as an average to make the whole story as robust and noiseless as possible.
And the Evolver is evaluating the exact same strategy again and again...
And results change by a big amount because of NSF positions (which are not controllable in any way in the Evolver process)...
... then I'd suggest that the "Best Metric" is not used from the last run (of many runs) but instead some average is calculated for all the runs of this one identical strategy.
... and I'd suggest to use the median as an average to make the whole story as robust and noiseless as possible.
QUOTE:
which are not controllable in any way in the Evolver process
Well, ok, this is not true. It is possible to use a very small position size in Preferences->Evolver and avoid NSF positions that way.
But this change removes one probably very interesting variable from the game, as long as it is not possible to set "Max Number of Open Positions" for the Evolver.
That's not how evolution works though. A generation doesn't somehow take an average of its trait across generations. The fact that its performance is so wildly variable SHOULD serve to possibly kill it during a generation run if it happens to have a bad run during one generation. The more stable performing strategies will survive.
QUOTE:
That's not how evolution works though. A generation doesn't somehow take an average of its trait across generations. The fact that its performance is so wildly variable SHOULD serve to possibly kill it during a generation run if it happens to have a bad run during one generation. The more stable performing strategies will survive.
@Glitch
A consistent fitness value is necessary for efficient progression of your evolutionary algorithm. Otherwise it is close to a random walk.
Randomness is usually used for mutation and crossover rules. Roulette wheel selection and various other selection algorithms such as tournament selection, rank selection and others are used to decide which individuals will survive based on their fitness value. Some algorithms additionally on the selection use a kind of "the best will survive" element. Of course, the size of the population also has an impact on the results of the evolver.
But it is certainly not state of the art to add randomness to the fitness value. In your words "That's not how evolution works though".
@DrKoch
In short: You might use the transaction weights in the strategies to produce consistent fitness values (strategy result outputs)
Detailed:
I don't know your pool of strategies. You could check if you can disable NSF positions or weight the transactions so that the outcome of a strategy is representative of its average performance (fitness) but consistent in the context used. Assuming you can turn off NSF positions my approach would be as follows.
1. determine an appropriate transaction weight (leading to a performance that is at the mean or median). This can be determined with MC first)
2. in order to achieve the first point, one can randomly select the weight, for example, until a value corresponds to the specifications. Once the value is found, it is set in the initialisation of the strategy. This should lead to consistent fitness values.
Actually, this procedure should also work if NSF positions are activated, as the weighting usually produces the same result.
If the NSF positions are necessary for the implementation to guarantee the selection, the chances of changing something from the outside look difficult. Selection is not controlled by changing the fitness value (in general).
>>But it is certainly not state of the art to add randomness to the fitness value<<
Maybe it should be, isn't evolution based on random mutations of genes?
Maybe it should be, isn't evolution based on random mutations of genes?
And look, the fact is that a strategy's performance can change dramatically from run to run depending on the position size. I think it would be disingenuous for the Evolver to just turn a blind eye to that.
QUOTE:
Maybe it should be, isn't evolution based on random mutations of genes?
Indeed, random mutations are part of evolution. So you can use randomness for that part.
And for various different parts that i mentioned above, crossover rates, selection strategies and so on.
Should you put randomness into the fitness value: No! (if you can avoid it, no)
QUOTE:
And look, the fact is that a strategy's performance can change dramatically from run to run depending on the position size. I think it would be disingenuous for the Evolver to just turn a blind eye to that.
This is a good practical and interesting task. My first suggestion is to find a (statistical) represtative individual of the strategy and use this in the evolving strategy. There can be different solutions but this could be one.
Fortunately, WL is so open that all of these ideas can already be realized, from custom Filter Sets to control what is accepted by the Evolver, to custom Scorecards that control what metric is used in the fitness test.
We'll never be able to please everyone, but hopefully we can build something so that everyone can please themselves, especially with sex coming in the next version!
We'll never be able to please everyone, but hopefully we can build something so that everyone can please themselves, especially with sex coming in the next version!
QUOTE:
A consistent fitness value is necessary for efficient progression of your evolutionary algorithm
I totally agree.
QUOTE:
You might use the transaction weights in the strategies to produce consistent fitness values
It is not possible to have transaction weights in genes for the evolver (currently).
QUOTE:
I don't know your pool of strategies
Nor do I . These strategies are created randomly by the evolver.
QUOTE:
check if you can disable NSF positions
Not possible with the current evolver. Also it is not helpful to "ignore" NSF positions. After all these are valid selctions of the trading strategy, i.e. the merit of the trading strategy is reflected by these NSF positions the same way as with "used" positions.
QUOTE:
My first suggestion is to find a (statistical) represtative individual of the strategy and use this in the evolving strategy.
Yes, I also think this is the way to go.
QUOTE:
these ideas can already be realized ... (with) custom Scorecards that control what metric is used in the fitness test.
Yes, I also think this is the way to go.
The basic idea goes as follows:
After a backtest is complete and for a single bar there are more entries than available capital, WL randomly chooses some of the proposed positions and records the remaining ones as NSF positions.
A new specialized ScoreCard will now take such a day and choose some different positions among the proposed positions (Regular + NSF Positions of that bar).
This process is repeated for every bar with NSF positions.
This way the Scorecard can simulate another backtest for the same strategy with different random set of Positions/NSF-Positions.
The ScoreCard will repeat such "newly randomized backtests" for a large number of "Bootstrap-Iterations". And calculate some average of the requested metric.
I created such a specialized "Evolver Scorecard" and the results are as follows:

The graph shows
* regular APR
* bootsrapped APR averaged with arithmetic mean and
* bootstrapped APR averaged with median.
The fluctuations are smaller but still very large. I think this is due the fact that these strategies have high NSF ratios. one of them for example of 3.94, i.e. a very high number (38905) of NSF positions compared to regular positions (9886). The Evolver seems to love such high NSF ratios.
After a backtest is complete and for a single bar there are more entries than available capital, WL randomly chooses some of the proposed positions and records the remaining ones as NSF positions.
A new specialized ScoreCard will now take such a day and choose some different positions among the proposed positions (Regular + NSF Positions of that bar).
This process is repeated for every bar with NSF positions.
This way the Scorecard can simulate another backtest for the same strategy with different random set of Positions/NSF-Positions.
The ScoreCard will repeat such "newly randomized backtests" for a large number of "Bootstrap-Iterations". And calculate some average of the requested metric.
I created such a specialized "Evolver Scorecard" and the results are as follows:
The graph shows
* regular APR
* bootsrapped APR averaged with arithmetic mean and
* bootstrapped APR averaged with median.
The fluctuations are smaller but still very large. I think this is due the fact that these strategies have high NSF ratios. one of them for example of 3.94, i.e. a very high number (38905) of NSF positions compared to regular positions (9886). The Evolver seems to love such high NSF ratios.
Are you not excluding them in your Evolver Filter?
Your description reminds me of the MC Tool using the same date scramble preference.
Although you improve the quality of the fitness value by generating some average there is still a noticable difference instead of working with consistent fitness values. The way i read your solution still varies the fitness scores for a single individual.
The main difference between a fitness score and genes is that the fitness score is the dependent variable in the set-up.
As we talk of a metaheuristic i give a different example.
Suppose the fitness function gives a distance to a target. The genes represent a path to the target. If the distance changes randomly for one and the same path, the GA will eventually reduce to a random search. The reason is, if one compares two individuals at two different times, the statement which path is the shorter one may contradict each other at both times (generations). Well, we do not search a path based on a fitness value representing a distance, but the mechanics keep to be the same for the GA.
The effect of an inconsistent fitness function is that it creates artificial noise.
In the best case, the GA still converges, but on average it takes much longer. The reason why this can still work is that even if the comparisons are contradictory, the statistical comparison would prefer the better individual in the long run. The GA simply needs N comparisons instead of one, so that reproduction becomes permanently accepted in the population.
Now, if the WL implementation of the GA would allow deterministic fitness values (using transaction weights), this would be an improvement.
There are some other considerations that can be discussed, anyway ...
The variance (NSF positions) of a strategy are the cause (based on the information in the discussion) for the behaviour. To use the average or median results are a very good idea imo, but finally you should pick(find) an individual that represent this average value and keeps producing a single output for the fitness function.
Good luck and enjoy exploring this topic.
Although you improve the quality of the fitness value by generating some average there is still a noticable difference instead of working with consistent fitness values. The way i read your solution still varies the fitness scores for a single individual.
The main difference between a fitness score and genes is that the fitness score is the dependent variable in the set-up.
As we talk of a metaheuristic i give a different example.
Suppose the fitness function gives a distance to a target. The genes represent a path to the target. If the distance changes randomly for one and the same path, the GA will eventually reduce to a random search. The reason is, if one compares two individuals at two different times, the statement which path is the shorter one may contradict each other at both times (generations). Well, we do not search a path based on a fitness value representing a distance, but the mechanics keep to be the same for the GA.
The effect of an inconsistent fitness function is that it creates artificial noise.
In the best case, the GA still converges, but on average it takes much longer. The reason why this can still work is that even if the comparisons are contradictory, the statistical comparison would prefer the better individual in the long run. The GA simply needs N comparisons instead of one, so that reproduction becomes permanently accepted in the population.
Now, if the WL implementation of the GA would allow deterministic fitness values (using transaction weights), this would be an improvement.
There are some other considerations that can be discussed, anyway ...
The variance (NSF positions) of a strategy are the cause (based on the information in the discussion) for the behaviour. To use the average or median results are a very good idea imo, but finally you should pick(find) an individual that represent this average value and keeps producing a single output for the fitness function.
Good luck and enjoy exploring this topic.
I think it's a mistake to consider a strategy the same individual each generation. Rather, it's an identical clone of the previous generation's individual.
It's like if it was a single celled organism that has a gene that causes it to randomly move right or left in random intervals.
In one generation, the random nature of its movement might cause it to get lucky and escape some predators, but in the next generation it might not. But regardless, it's still random motion. Maybe another random gene is a clear benefit or a clear drawback, it'll all get resolved as the evolution continues.
The fitness function itself isn't random at all.
It's like if it was a single celled organism that has a gene that causes it to randomly move right or left in random intervals.
In one generation, the random nature of its movement might cause it to get lucky and escape some predators, but in the next generation it might not. But regardless, it's still random motion. Maybe another random gene is a clear benefit or a clear drawback, it'll all get resolved as the evolution continues.
The fitness function itself isn't random at all.
QUOTE:
I think it's a mistake to consider a strategy the same individual each generation.
Of course it is not. It is a "new" individual created on the GA rules. It can be constructed as an individual from the previous generation. The output of the fitness function is unpredictable for identical individuals. Within a generation or for different generations.
The example I described for two individuals is of course a simplified description (to describe the idea). Although GA can produce clones, the effect does not only apply to a complete chromosome. The same effects are also given for a group of genes (parts of the chromosome).
I know that problems exist where you simply can not create consistent fitness values but you still use a GA solver. But these fitness functions have to deal with the above effects. The current application does not belong to that group in all consequences.
Well, i don't want to convince anybody here.
This is a meta-heuristic. You can just use your solution for a different (easier) problem and play with it and observe what effects will happen.
Your Response
Post
Edit Post
Login is required