Request
If data for a symbol has already been loaded and more data for the symbol is read during the loading process, it should be appended to the existing data set.
Details
The current behavior is that WL only uses the last file read.
Although this point has been discussed before and there are different opinions on this topic, I would still like to make an explicit FeatureRequest.
More arguments can be found in #22 of the following thread.
https://www.wealth-lab.com/Discussion/Permanent-conversion-from-ASCII-to-binary-data-8320
Finally, the use case is to get a simple tool for an ASCII data update process.
An ascii provider can provide files that contain the current data rather than the historical data.
This is a very common scenario. Since WL already reads multiple files, it only needs to determine if a symbol has been red in the current loading process. If there is another file for the symbol, it needs to append the data to the currently loaded data set.
The user only needs to specify the location for the ASCII data, as is the right now.
If data for a symbol has already been loaded and more data for the symbol is read during the loading process, it should be appended to the existing data set.
Details
The current behavior is that WL only uses the last file read.
Although this point has been discussed before and there are different opinions on this topic, I would still like to make an explicit FeatureRequest.
More arguments can be found in #22 of the following thread.
https://www.wealth-lab.com/Discussion/Permanent-conversion-from-ASCII-to-binary-data-8320
Finally, the use case is to get a simple tool for an ASCII data update process.
An ascii provider can provide files that contain the current data rather than the historical data.
This is a very common scenario. Since WL already reads multiple files, it only needs to determine if a symbol has been red in the current loading process. If there is another file for the symbol, it needs to append the data to the currently loaded data set.
The user only needs to specify the location for the ASCII data, as is the right now.
Rename
One ASCII file per symbol has always been the ASCII provider's modus operandi. We are not excited by making the provider code base even more complex if we'd introduce such extraneous logic. It's in everyone's best interest to keep the software simple inside.
It's much easier for the end user to come up with a script or batch tool for his own and very specific use case (to 'glue' two files together) than to allocate our time and effort for the development and its imminent maintenance.
Notepad++, PowerShell, Python, batch file, AutoIT3, C#... - there are countless ways to combine two ASCII files together and automate the process for any power user.
It's much easier for the end user to come up with a script or batch tool for his own and very specific use case (to 'glue' two files together) than to allocate our time and effort for the development and its imminent maintenance.
Notepad++, PowerShell, Python, batch file, AutoIT3, C#... - there are countless ways to combine two ASCII files together and automate the process for any power user.
1. It is not easier for the common user.
2. Merging 250GB of data daily does not make any sense, when you add only some MB. Especially not if you need a fraction of it for a special data set. A permanent merge is simply not necessary, and definitely not on daily basis. Even not if we talk of only 2GB data that needs to be maintained.
3. But the point that confuses me the most is, that you still say you are not able to attach data to an already existing data object. Everything should already be there. So, what is the real problem? I simply can not be code complexity and maintenance!
It does not violate general agreements, because the data is only used by your software. You can handle it like you want. After all, you do not output multiple files per symbol. That would be an argument i could accept.
No, the development effort, code complexity, maintenance and standards compliance are not a problem here.
We can talk about concrete implementation difficulties, but let's stop talking about conceptual content.
This kind of feature dosn't need to be discussed on that level. It is about an implementation detail in an existing logic.
So, if you load a "symbol.txt", you will keep the data in a data structure. I guess you allocate dynamic memory, because of different data sizes. Now, if you read another "symbol.txt" (the same symbol) you only need to implement two essential steps.
First, check if the name has already been loaded and if so, reallocate the memory and add the data from the current file. It is only about the loading process. Everything else keeps to be the same.
You still think in small dimensions. We are talking of 250GB Data 7300+ files.
I did not count the lines so far,but extrapolated we talk about 11 Billion single lines of data.
Even a fraction of this amount of data should not be managed manually.
And it doesn't have to be at all. The data can be loaded on demand. There is no need to merge the data at all.
The development effort for this is ridiculous compared to the potential benefit.
2. Merging 250GB of data daily does not make any sense, when you add only some MB. Especially not if you need a fraction of it for a special data set. A permanent merge is simply not necessary, and definitely not on daily basis. Even not if we talk of only 2GB data that needs to be maintained.
3. But the point that confuses me the most is, that you still say you are not able to attach data to an already existing data object. Everything should already be there. So, what is the real problem? I simply can not be code complexity and maintenance!
It does not violate general agreements, because the data is only used by your software. You can handle it like you want. After all, you do not output multiple files per symbol. That would be an argument i could accept.
No, the development effort, code complexity, maintenance and standards compliance are not a problem here.
We can talk about concrete implementation difficulties, but let's stop talking about conceptual content.
This kind of feature dosn't need to be discussed on that level. It is about an implementation detail in an existing logic.
So, if you load a "symbol.txt", you will keep the data in a data structure. I guess you allocate dynamic memory, because of different data sizes. Now, if you read another "symbol.txt" (the same symbol) you only need to implement two essential steps.
First, check if the name has already been loaded and if so, reallocate the memory and add the data from the current file. It is only about the loading process. Everything else keeps to be the same.
QUOTE:
Notepad++, PowerShell, Python, batch file, AutoIT3, C#... - there are countless ways to combine two ASCII files together and automate the process for any power user.
You still think in small dimensions. We are talking of 250GB Data 7300+ files.
I did not count the lines so far,but extrapolated we talk about 11 Billion single lines of data.
Even a fraction of this amount of data should not be managed manually.
And it doesn't have to be at all. The data can be loaded on demand. There is no need to merge the data at all.
The development effort for this is ridiculous compared to the potential benefit.
Hi MIH, we have no problem keeping the request open, but from our perspective this is, so far, a single user (you) request. If more users vote on it then it will rise to the top of the Wish List. As you know, we have nearly 100 requests in that queue, so, while I'm sure you feel that this is one of the most important items, not everyone else shares your viewpoint.
Furthermore, I would question whether the ASCII provider is the right place to add such complexity at all. It's not such a simple development task as you're assuming. For that quantity of data, I'd personally never use ASCII but instead I'd create a custom Historical Data Provider that would store the data in a binary format and update it automatically.
If there's a real demand for the creation of such a provider, we can take it on once the request gets more support.
Furthermore, I would question whether the ASCII provider is the right place to add such complexity at all. It's not such a simple development task as you're assuming. For that quantity of data, I'd personally never use ASCII but instead I'd create a custom Historical Data Provider that would store the data in a binary format and update it automatically.
If there's a real demand for the creation of such a provider, we can take it on once the request gets more support.
Ok, it is like it is.
For me it's quite hard to believe that this implementation detail is a challenge in an existing framework. Unless libraries are used that cannot or must not be changed.
It's no secret that i am talking of FirstRate Data. That they provide multiple files is absolutely correct. The historical data of about 30-40 GB compressed, of course, you do not want to download every day because a few KB per file have been added.
Future data can, of course, only be offered at the time of creation. It is logical that the data recipient is ultimately left with the task of merging the data. The "one file" principle does not work here.
I was able to download the complete intraday data for more than 15 years in less than an hour. I have been collecting data through Data Manager for more than 3 months now. On the one hand complete data for 15 years in one hour, on the other hand 3 months of nightly downloads for incomplete data and other limitations.
I already accept your point of view. My next comment is not to convince anyone, it is just to have a conversation about this interesting topic.
If you look at the issue on a strategic level, it looks like this to me. The retail consumer is getting more and more opportunities to acquire this data at acceptable prices.
There will be more suppliers and more buyers. Text formats / CSV formats will become the standard, since the simple user cannot do anything with binary formats without appropriate software. And very few data providers will focus on a specific software.
The essence of the software is to process this data. In the future, WL will also have to meet higher requirements in this context. The software depends on the quantity and quality of data that can be processed. To put it a bit dramatically, without data, WL is worth nothing.
In my career, I also worked as a product owner for a while. Even if the stakeholders have permanent requirements, the direction is determined by the product owner, as you are doing now. Ultimately, you have to weigh up whether the day-to-day business also meets a strategic goal.
Thanks Eugene,
Thanks Glitch
For me it's quite hard to believe that this implementation detail is a challenge in an existing framework. Unless libraries are used that cannot or must not be changed.
It's no secret that i am talking of FirstRate Data. That they provide multiple files is absolutely correct. The historical data of about 30-40 GB compressed, of course, you do not want to download every day because a few KB per file have been added.
Future data can, of course, only be offered at the time of creation. It is logical that the data recipient is ultimately left with the task of merging the data. The "one file" principle does not work here.
I was able to download the complete intraday data for more than 15 years in less than an hour. I have been collecting data through Data Manager for more than 3 months now. On the one hand complete data for 15 years in one hour, on the other hand 3 months of nightly downloads for incomplete data and other limitations.
I already accept your point of view. My next comment is not to convince anyone, it is just to have a conversation about this interesting topic.
If you look at the issue on a strategic level, it looks like this to me. The retail consumer is getting more and more opportunities to acquire this data at acceptable prices.
There will be more suppliers and more buyers. Text formats / CSV formats will become the standard, since the simple user cannot do anything with binary formats without appropriate software. And very few data providers will focus on a specific software.
The essence of the software is to process this data. In the future, WL will also have to meet higher requirements in this context. The software depends on the quantity and quality of data that can be processed. To put it a bit dramatically, without data, WL is worth nothing.
In my career, I also worked as a product owner for a while. Even if the stakeholders have permanent requirements, the direction is determined by the product owner, as you are doing now. Ultimately, you have to weigh up whether the day-to-day business also meets a strategic goal.
Thanks Eugene,
Thanks Glitch
I'll reach out to First Rate data and maybe the right approach is to create a dedicated Provider for them. Perhaps they'd even be able to help us promote the Provider amongst their customers.
I am not sure I understand you now. FirstRate Data gets the data directly from the exchanges. Or what do you mean by provider in connection with FirstRate Data?
You can find more information at https://firstratedata.com/about/FAQ
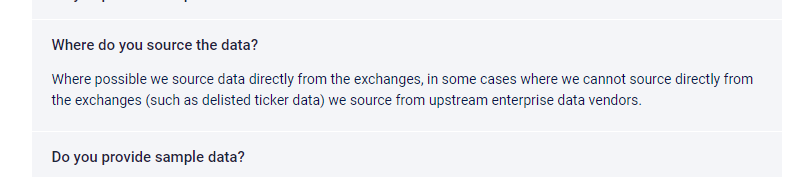
I guess you mean exactly the opposite. Do you want to provide their data?
Sorry, I'm having a language barrier here right now, maybe you can help me out.
I guess you mean exactly the opposite. Do you want to provide their data?
Sorry, I'm having a language barrier here right now, maybe you can help me out.

Hi, any news on this topic?
Not yet, I’ve been working through the wish list requests with more votes first.
Your Response
Post
Edit Post
Login is required